The Pridentifier is a research project with the goal to identify the original printer of a given print (even for small snippets of a print). To automatically identify the original printer, the individual “handwriting” of every printer has to be learned in advance. Therefor machine learning tasks and image processing algorithms are used.
Problem
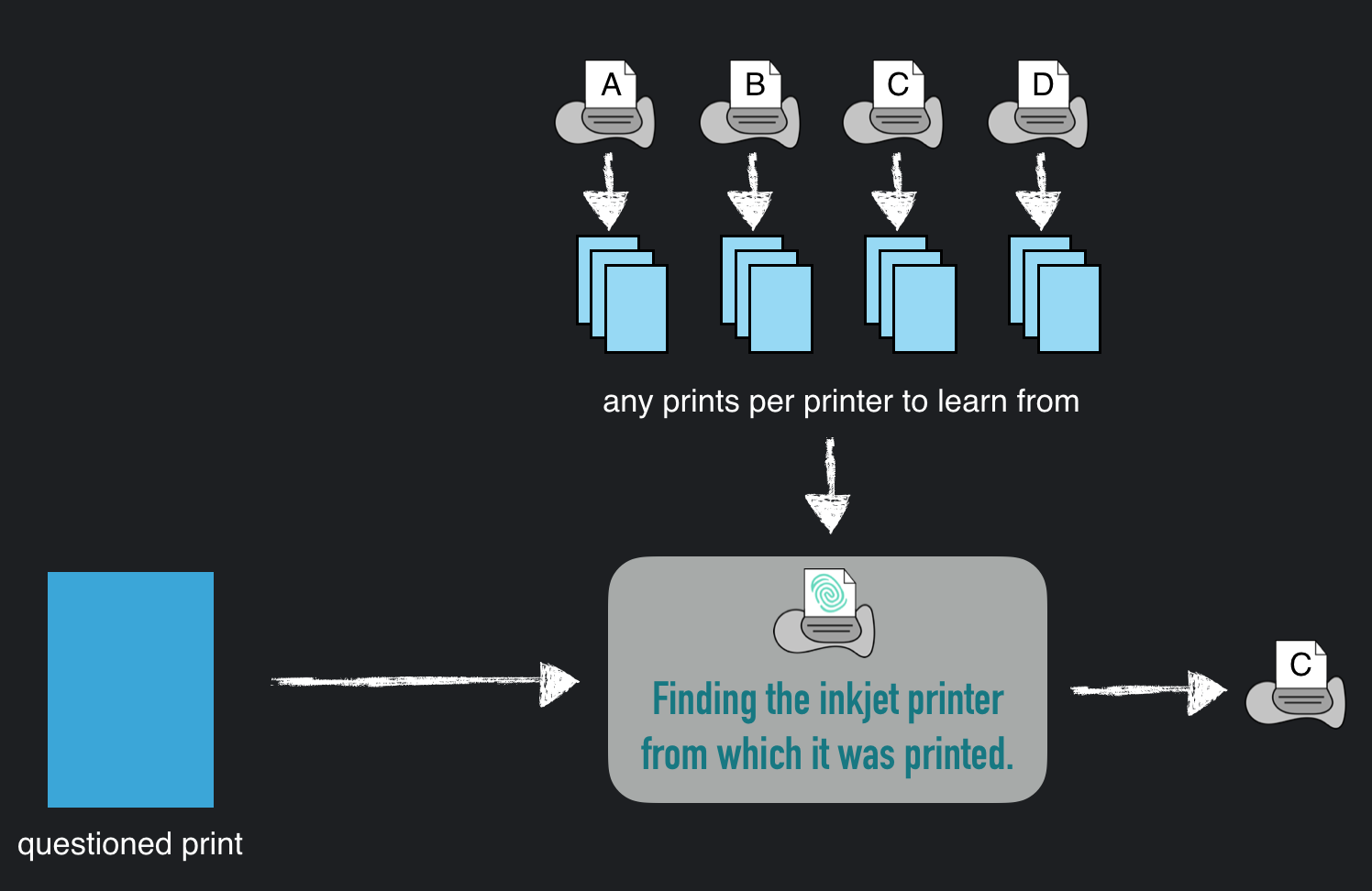
You want to figure out the original printer of any given document (identitity card, banknote, contract, letter etc.). But all you have is the given print and a number of printers. You know that one of the printers is the original printer of the document. But you don’t know which one of them.


Solution
With the Pridentifier you can let the program learn the individual printing behavior independent of the printed motive. Therefor you only need a set of arbitrary printings per printer. Those printings you need to upload to train the Pridentifier. After that (1) training step you can use the Pridentifier as (2) printer identifier. You only need to upload any unknown (questioned) print. Then the Pridentifier will tell you from which printer that unknown print was printed.
Using the Pridentifier Software
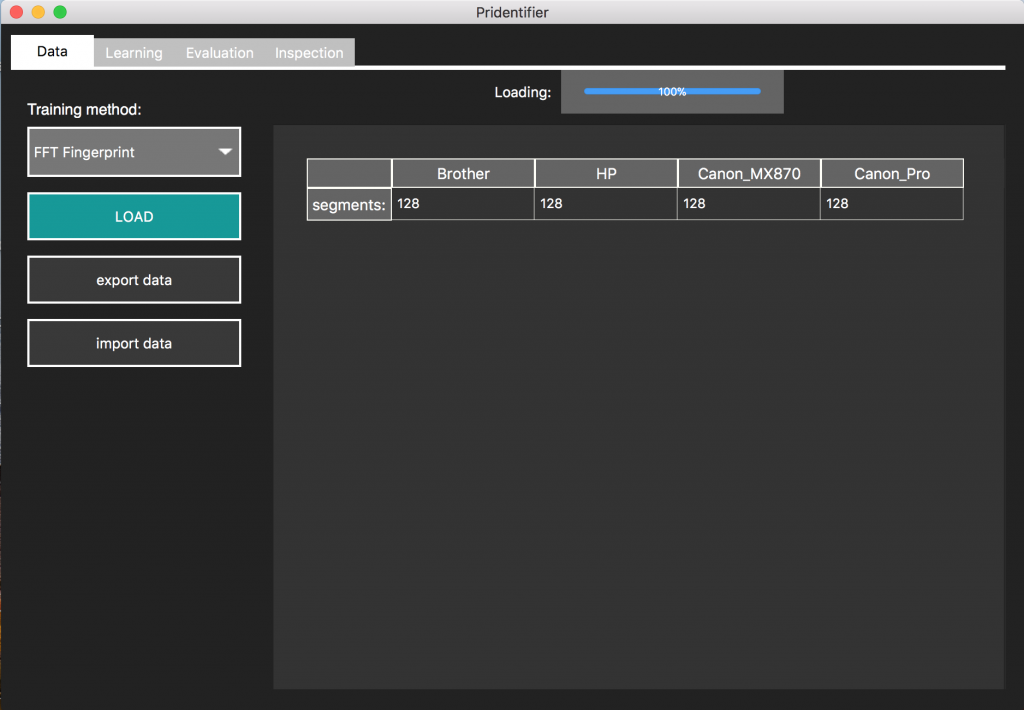
(1) Training step
For the training step you need to print several documents from different printers. For instance choose a digital source of an ID-card and print it on each printer. To achieve a good classifier several different printings are used.





As you can see in the zoomed snippet (cyan/aqua box) each printer has its own way to compose ink to create the whole document image. When looking at the zoomed snippet you maybe already guess that the different printers can be distinguished by analyzing the repetition and arrangement of the ink drops. That is exactly what the Pridentifier does.
(2) Identifying step
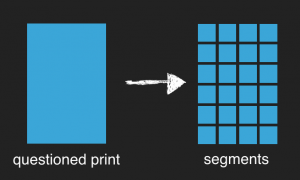
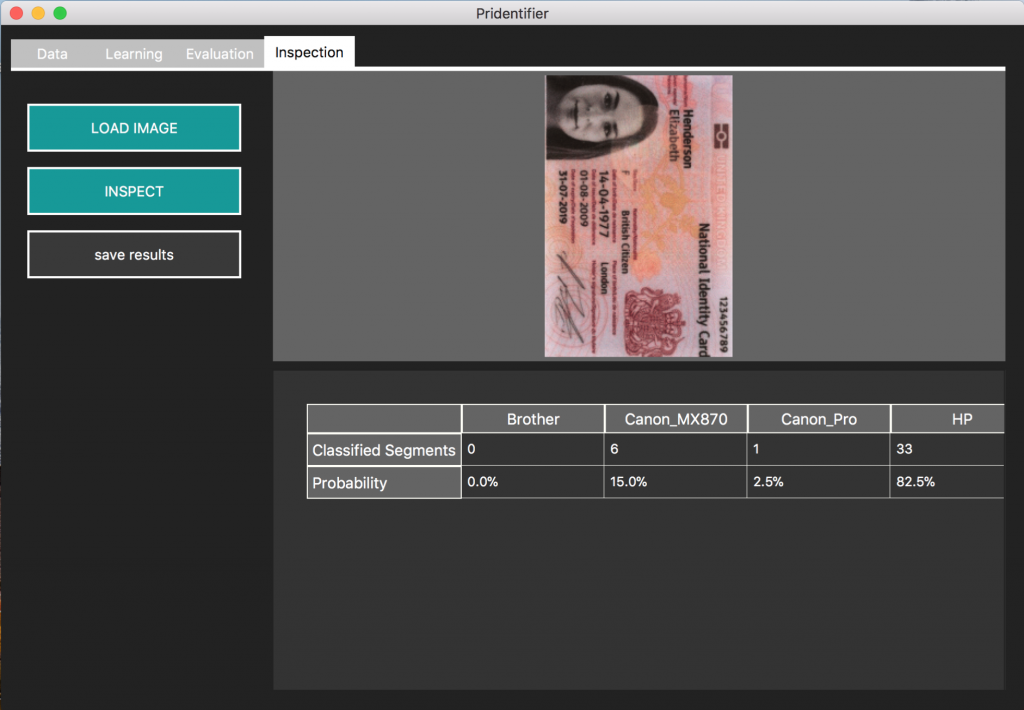
When the Pridentifier is already trained with several prints of the different printers, you can use the Pridentifier to identify the origin printer of a questioned print. You can choose a small snippet of a document to identify the origin printer.
The Pridentifier returns the probability by classifying for every 512×512 px snippet on the document (see figure below). If every snippet was classifier as a print of a certain printer, the similarity is 100%. The larger the size of the questioned print, the more likely is the similarity with the origin printer.
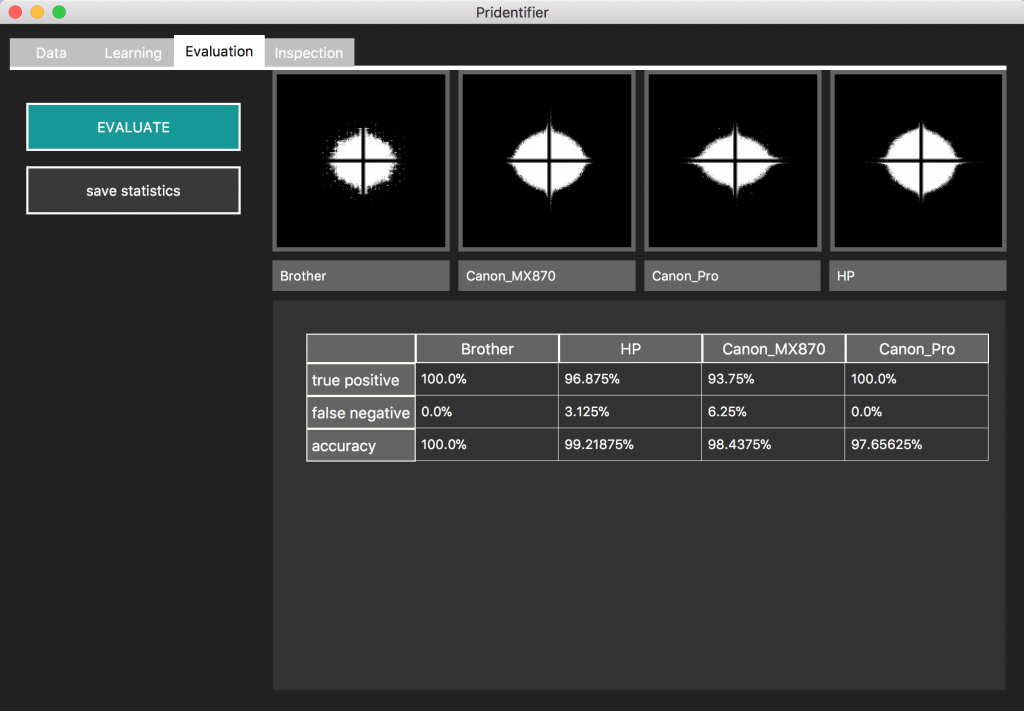
Statistics
In our examination of 4 printers (Brother, Canon MX870, Canon Pro and one HP printer) we achieved the following accuracy and classification failure statistics.

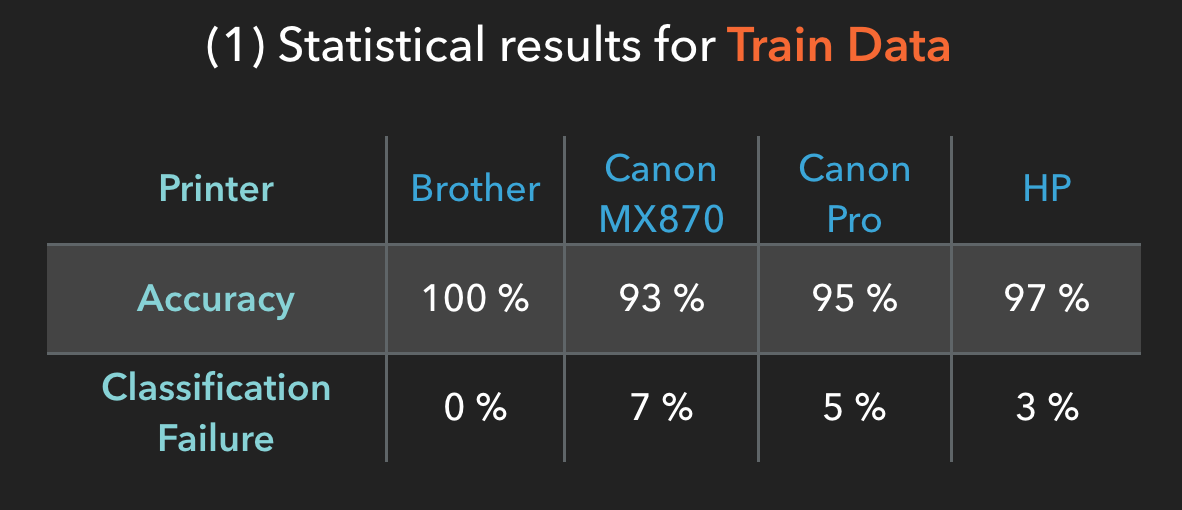
This statistic is the prediction for one snippet (512×512 px). If a larger image is used, we can cut the image into several 512×512 px snippets and the probability increases.